论文笔记|Towards a Universal Synthetic Video Detector: From Face or Background Manipulations to Fully AI-Generated Content
1. Introduction
DeepFake和相关检测技术主要为面部修改,但现有的文本到视频(T2V)和图像到视频(I2V)生成模型(AVID、GTA-V、T2V/I2V)支持任意内容的更改、合成,因此需要通用的AIGVC检测器。
| 方法 | 面部操纵 | 背景操纵 | T2V/I2V |
|---|---|---|---|
| 现有方法 | √ | × | × |
| 使用交叉熵损失的全帧检测 | √ | × | ≈ |
| UNITE | √ | √ | √ |
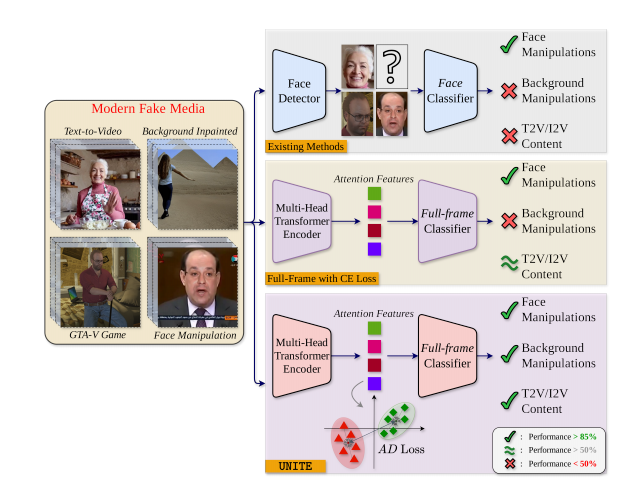
本文提出:the Universal Network for Identifying Tampered and synthEtic videos(UNITE,用于识别篡改和合成视频的通用网络)
- 可以捕获全帧操纵(Full-frame Manipulation),无论是否有人脸
- 将检测功能扩展到没有人脸、非人类主体和复杂背景修改的场景
- 引入“Attention Diversity” Loss,相比交叉熵损失,鼓励关注视频的不同区域
- 采用创新的训练策略
2. Related Work
2.1 Face-centric DeepFake Detection 专注于人脸的DeepFake检测
空间不一致性(图像内):
- Concas’:在高频域追踪特定面部特征,缺乏普适性
- PUDD:真实视频中学习特定人物的原型,对真实的生物特征和行为模式进行建模,在实际场景中效果有限
- LAA-Net:通过一个多任务注意力模块来提升泛化能力,使用热力图和自一致性回归检测伪影特征。需要逐帧分析视频静态画面,产生巨大的计算开销,限制了扩展性
生物特征一致性(针对个体):
- DPNet:通过动态特征表示实现可解释的、基于原型的非自然运动检测
- IDReveal:在真实数据上进行的度量学习
- PUDD也属于此类
- 依赖真实参考视频作为前提条件,导致其难以应对现实场景中的深度伪造检测。
时序不连续性(图像变化):
- TI2Net:减去连续帧的特征
- TALL:从随机时间戳获取的四个连续帧构建复合“缩略图”图像
- StyleGRU:时序特征目标化,严格限制于裁剪的面部区域,仅适用于面部操纵
2.2 Synthetic Video Detection 合成视频检测
合成视频检测仍是一个很少被探索的领域。
DeMamba连续扫描方法:
- 分析视频帧的小范围区域,捕捉像素在时空维度上的变化规律。
- 其连续扫描技术能更精准追踪细微变化和模式特征,从而更易识别经过处理或伪造的内容。
缺点:未经主流DeepFake数据集上的验证
(方法附一个百万级T2V/I2V数据集)
3. Method
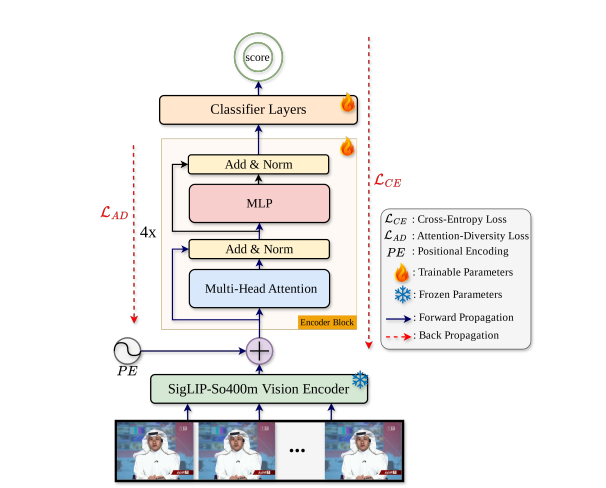
将表征学习(由SigLIP负责)与法证学习(由可训练的Transformer负责)明确分离。
注意力图源自编码器模块的输出,主要用于计算AD Loss(3.4),并直观展示模型在分类过程中对视频帧中不同空间区域的优先级分配(图3)。
3.1 Problem Setup 问题建模
采样策略:
- 隔1帧抽取,$n_f=64$个连续帧合成一个片段(不足填充),记为一个数据单元$v$
- 原始视频标签已知,每个数据单元的标签$l$与源视频相同
- 最终得到视频数据集$V={(v_i,l_i)|i=1,2,…,N}$
该策略同时作为数据增强方法,在不额外收集数据的情况下增加训练样本的数量。
3.2 Domain-Agnostic Feature Extraction 域无关特征提取
采用冻结的SigLIP-So400m模型(“shape-optimized”VIT)作为特征提取器。
使用30亿个多样化样本和sigmoid损失函数进行对比训练。
既保持了紧凑的参数规模(4亿参数),又能够捕捉稳健且通用的特征。
深度预训练使SigLIP特别擅长提取领域无关表示,这对于应对DeepFake数据集和真实场景中遇到的显著差异至关重要。
对于样本$v_i\in V$的每一帧(Resize to 384×384×3),提取其特征:
$$
e_j=SigLIP(f_j)\in \mathbb{R}^{t_s\times d_s}, j=1,2,…,n_f
$$
- 编码长度$t_s=729$,特征维度$d_s=1152$
按照原始顺序拼接得到视频片段编码$\xi_i\in \mathbb{R}^{nf\times ts\times ds}$,最终得到编码视频数据集$V_{\xi}={(\xi_i,l_i)|i=1,2,…,N}$,作为Transformer的输入。
3.3 Learnable Transformer Architecture 可学习的Transformer架构
UNITE架构是基于MHSA(Multi-Head Self-Attention)机制的Transformer,专为视频分类任务设计,支持深度(内部堆叠的编码器块数量)调节。
深度更大的架构能捕捉更复杂的特征,但会增加计算复杂度,最终选择了深度为4的架构(通过消融实验确定,实验位于4.4)
3.3.1 Encoder Block 编码器块
- MHSA:架构使用$n_h=12$个注意力头
- 能捕捉帧间多样化的交互关系与依赖性
- 归一化点积注意力机制:有效环节梯度爆炸
- Add&Norm:残差连接和层归一化
- 残差连接:将输入直接添加到输出,缓解深层网络中的梯度消失问题
- 层归一化:归一化到正态分布,稳定训练过程,加速收敛
- Dropout:在注意力机制后部分应用,抑制过拟合
- MLP:前馈网络,用于对特征进行非线性变换
- 中间用GELU激活函数,通过非线性特征变换显著提升模型表达能力
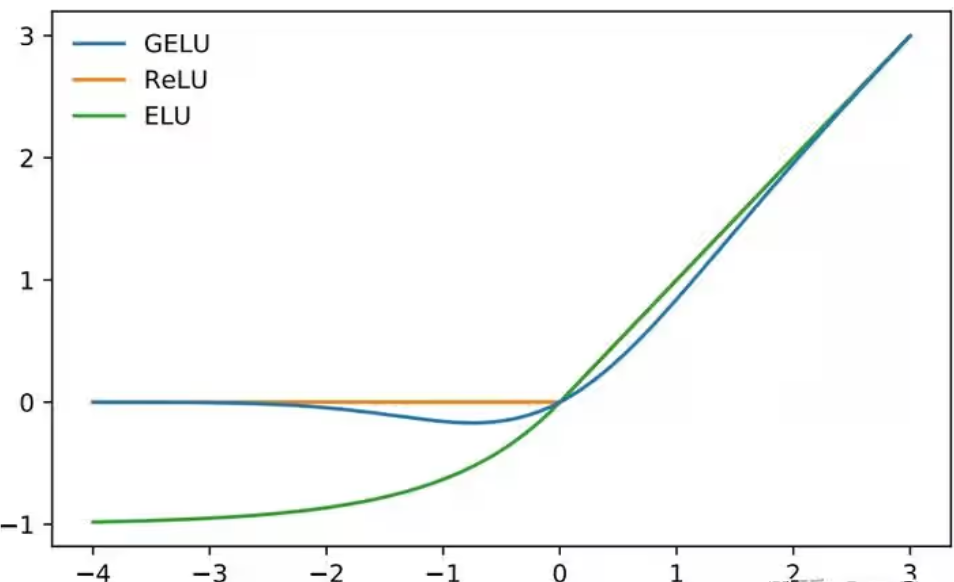
该部分参考Transformer的标准架构设计,适当调整以适应视频分类任务。
3.3.2 Positional Encoding 位置编码
采用与原始transformer相同的正弦余弦位置编码方案。
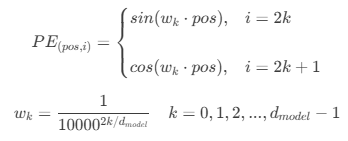
3.4 Attention-Diversity Loss 注意力多样性损失
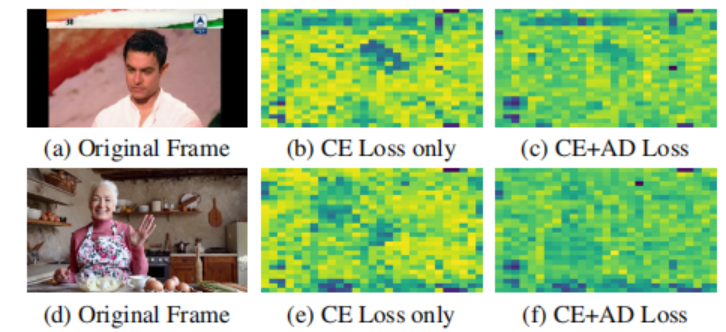
仅使用CE Loss训练MHSA Transformer时,其注意力图会自然过度聚焦于画面中的人脸区域。
为了解决这个问题,本文引入了Attention-Diversity Loss(AD Loss),让注意力头关注视频的不同区域。
池化特征向量(样本级)代表了每个注意力头和每帧的压缩、加权特征向量:
$$
\mathcal{P} = \sum_{j=1}^{l_a} \sum_{k=1}^{d_a} \mathcal{A}{h,j,k} \cdot \xi{f,j,k}
$$
- 池化特征向量$\mathcal{P} \in \mathbb{R}^{n_h\times n_f}$
- 注意力输出$\mathcal{A} \in \mathbb{R}^{n_h\times t_s\times d_s}$
- 视频编码$\xi \in \mathbb{R}^{n_f\times t_s\times d_s}$
- $n_h$:注意力头数,$n_f$:帧数,$t_s$:编码长度,$d_s$:特征维度
- $f$:帧索引,$j,k$:注意力图的空间位置
动态特征中心(类别级)学习:
$$
C^{\tau} = C^{\tau-1} - \eta \left(C^{\tau-1} - \frac{1}{B} \sum_{b=1}^{B} \mathcal{P}_b \right)
$$
- $C^{\tau} \in \mathbb{R}^{n_h\times n_f}$:第$\tau$次迭代的动态特征中心,$C^0=0$
- $B$:当前批次大小
- $\eta$:特征中心更新的学习率,0.05
类内损失,促使相似样本聚集在一起:
$$
L_{within} = \max(|| \mathcal{P} - C ||2-\delta{within},0)
$$
- $||x||_2$:L2归一化
- $\delta_{within}$:超参数,阈值内视为0,鼓励类内样本接近特征中心
类间损失,促使不同类别的样本分离:
$$
\mathcal{L}{\text{between}} = \sum{\substack{k \neq l \\ (k, l) \in (n_h, n_h)}} \max \left(\delta_{\text{between}} - |C_k - C_l|_2, 0 \right)
$$
- $C_k,C_l$:不同类别的动态特征中心
- $\delta_{between}$:超参数,鼓励类间特征中心相互远离
最终的AD Loss:
$$
\mathcal{L}{AD} = \mathcal{L}{within} + \mathcal{L}_{between}
$$
最终的总损失函数:
$$
\mathcal{L}{\text{UNITE}} = \lambda_1 \mathcal{L}{CE} + \lambda_2 \mathcal{L}_{AD}
$$
- $\lambda_1,\lambda_2$:损失加权超参数,均设为0.5
3.x 思考
- 为什么UNITE使注意力分布均衡?
- Transformer的MHSA机制本身具有捕捉多样化特征的能力
- AD Loss通过类内和类间损失的设计,明确鼓励模型关注不同区域
- 为什么AD Loss能使模型关注更多区域?
- 如果所有注意力头都集中在人脸,它们提取的特征 $\mathcal{P}$ 将高度相似与冗余。
- 类内损失:要求真实类别的特征中心($\mathcal{C}{\text{real}}$)和伪造类别的特征中心($\mathcal{C}{\text{fake}}$)在特征空间中保持至少 $\delta_{\text{between}}$ 的最小距离。
- 两个类别中心保持清晰的分离裕度,模型不能只依赖人脸这种单一、局部且可能误导性的线索。
- 类间损失:强制同一类别的池化特征向量($\mathcal{P}$)必须紧密地聚集在其类别中心 ($\mathcal{C}$) 附近。
- 这促使模型学习到更具区分力的特征,避免过度依赖单一区域。
- 方法概述
- 提取域无关特征、使用可学习的Transformer进行分类、引入AD Loss促进注意力多样化
4. Experiments
4.1 Datasets 数据集
| 数据集 | 用途 | 类型 | 说明/备注 |
|---|---|---|---|
| FaceForensics++(FF++) | 训练、测试 | 面部操纵 | c23i.e.,medium-quality |
| SAIL-VOS-3D | 训练 | GTA-V游戏 | 包含合成的(非AI生成的)GTA-V游戏视频 以真人为主体,适用于DeepFake检测 |
| CelebDF | 测试 | 面部操纵 | |
| DeeperForensics | 测试 | 面部操纵 | |
| DeepfakeTIMIT | 测试 | 面部操纵 | |
| Hififace | 测试 | 面部操纵 | |
| UADFV | 测试 | 面部操纵 | |
| AVID | 测试 | 背景操纵 | AVID模型的公开样本视频 |
| GTA-V | 测试 | 合成视频 | GTA-V游戏视频 |
| Demamba | 测试 | 合成视频 | |
| NYTimes | 测试 | 野外视频 | 纽约时报DeepFake测试的公开视频 |
4.2 Results & Discussion 结果与讨论
| 评估指标 | 说明 |
|---|---|
| AUC | 精确召回曲线(Precision-Recall Curve)下的面积 |
| Precision@0.5 | 精确率,预测为正样本中实际为正样本的比例,置信度0.5 |
| Recall@0.5 | 召回率,实际为正样本中被正确预测为正样本的比例,置信度0.5 |
| Precs@Rec=0.8 | 在召回率为0.8时的精确率 |
| Rec@Prec=0.8 | 在精确率为0.8时的召回率 |
| 训练参数 | 值 | 说明 |
|---|---|---|
| optimizer | AdamW | 结合了Adam的自适应学习率和权重衰减的优化器 |
| learning rate | 1e-4 | 初始学习率,每1000步衰减率0.5 |
| $\delta_{between}$ | 1.0 | AD Loss的类间距离阈值 |
| $\delta_{within}$ | [0.01, -2, 1(多分类)] | AD Loss的类内距离阈值 |
| batch size | 32 | 每次迭代处理的样本数量 |
| epochs | 25 | 训练数据集的完整迭代次数 |
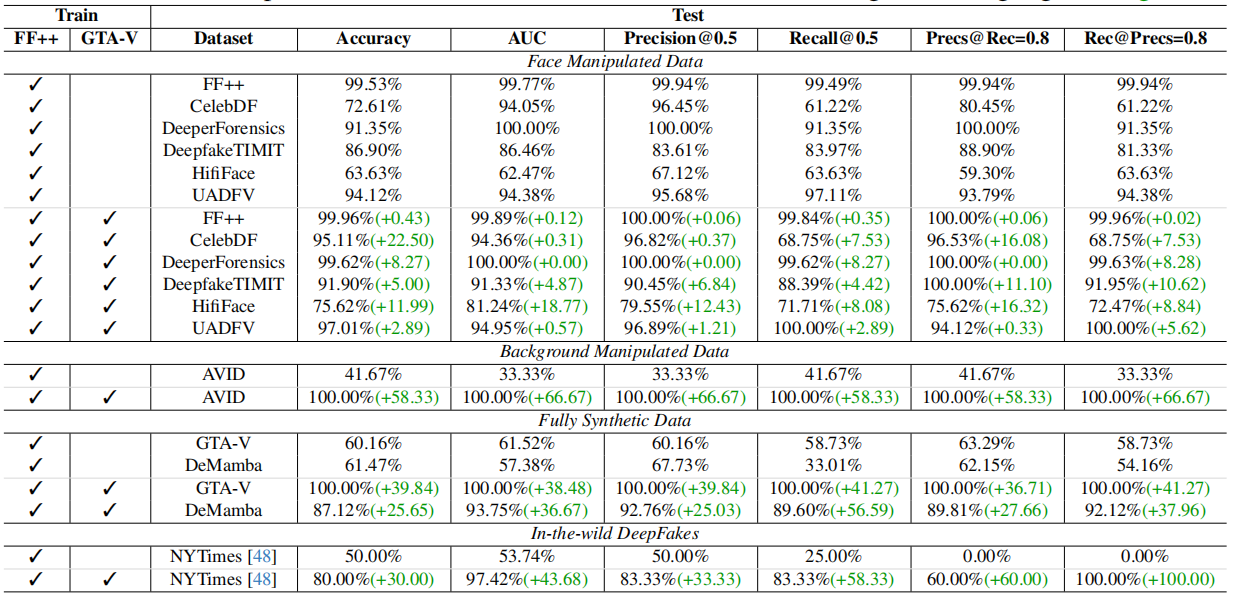
概述:
- 加上GTA-V训练相比只有FF++训练,测试性能提升显著(特别在非人脸任务)。
- 同样使用FF++和GTA-V训练,加上AD Loss后,注意力热力图分布更均匀,表明模型能关注视频的更多区域,提升了检测性能。
- 即使在面部操纵任务中,UNITE也优于现有的SOTA方法
- 虽然未经全AI生成的其他类型视频训练,但在未见的数据集上表现良好
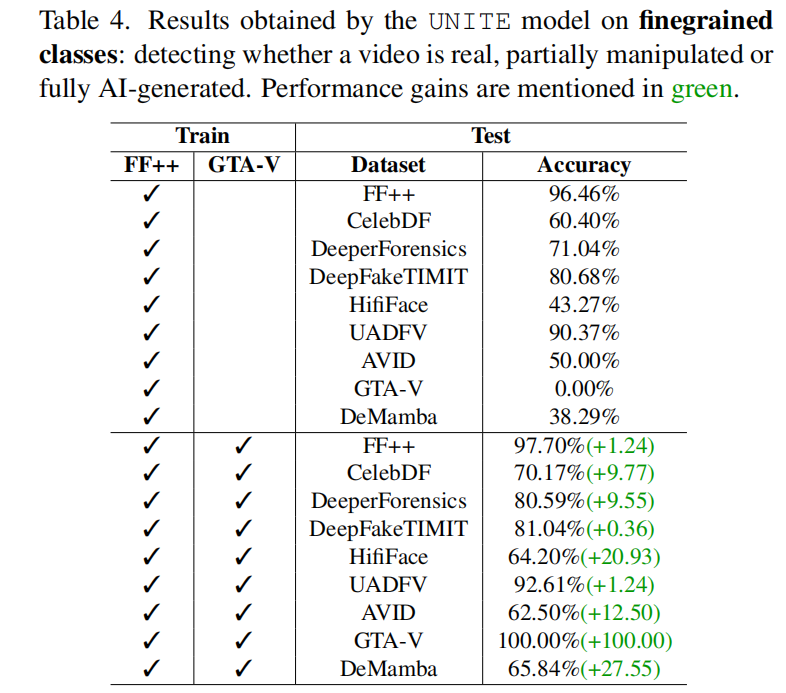
4.3 Fingrained Evaluation 细粒度评估
将数据分为三类:真实视频、部分操纵视频、完全AI生成视频。
使用UNITE进行三分类,在加上GTA-V训练时表现良好
4.4 Ablation Study 消融实验
评估AD Loss对性能的影响:

- 对比仅CE Loss、仅AD Loss、联合使用CE和AD Loss的效果,联合使用效果最佳
- 合成视频数据:在DeMamba数据集上,无论是否加上GTA-V训练,仅CE Loss的性能无明显变化,使用AD Loss后性能提升明显
- 背景操纵数据:在AVID数据集上,仅使用FF++训练,仅CE Loss性能为0(因为训练没有背景操纵样本),使用AD Loss后性能提升明显
- 人脸操纵数据:在CelebDF、UADFV等数据集上,使用AD Loss后性能有所提升,说明模型学习到更具区分度的注意力图特征
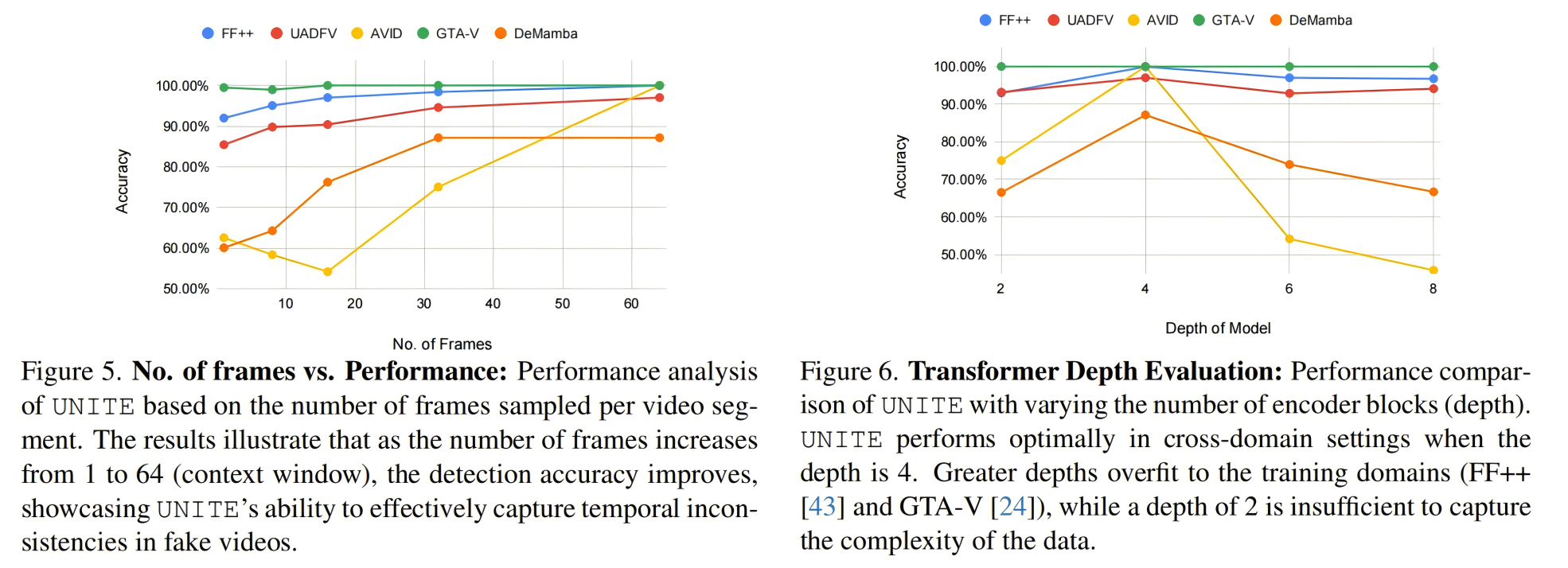
- 帧数与性能关系:随着包含更多帧数,模型性能逐步提升,凸显了模型通过利用时间线索显著提升检测精度的能力
- Transformer深度与性能关系:深度为4时性能最佳,过浅或过深均导致性能下降
Ex. Fisher 判别分析原理
经典FLDA(Fisher Linear Discriminant Analysis)是一种线性分类方法,旨在找到一个投影方向,使得投影后的类间距离最大化,类内距离最小化。
$$
J(w) = \frac{w^T S_B w}{w^T S_W w}
$$
- $S_B$:类间散布矩阵,衡量不同类别之间的分布差异
- $S_W$:类内散布矩阵,衡量同一类别内部的分布差异
- $w$:投影向量
经典 LDA 只能进行线性判别,无法处理高维数据中的复杂非线性关系。
深度网络的 Fisher 判别分析(DFDA)的基本原理:使用深度神经网络(DNN)作为特征提取器,将原始的高维非线性数据映射到一个低维的、更容易线性可分的空间,在这个空间中最大化 Fisher 判别准则。
- 特征提取层: 由一个多层的深度神经网络(如 CNN、MLP 等)组成,负责将输入数据$X$转化为特征表示$Z=f(X)$
- 判别损失层:在特征表示$Z$上计算 Fisher 判别准则(作为损失函数的一部分),并与其他任务相关的损失(如交叉熵损失)结合进行联合优化
- 分类层:通常是一个全连接层,作为线性分类器
损失函数:
$$
L = L_{task} + \lambda L_{Fisher}
$$