论文笔记|Human-centered mechanism design with Democratic AI
论文:Human-centered mechanism design with Democratic AI(Nature2022)
译:使用民主AI进行以人为本的机制设计
摘要
- 提出难题:构建符合人类价值观的人工智能
- 本文提出了一种人类参与的研究pipeline“民主AI”,通过强化学习设计出符合人类多数偏好的社会机制
- 实验场景:若干人类参与“在线投资游戏”,独立决策个人存蓄和集体利益平衡
- 方法:分别由人类和AI设计分配机制,参与者投票;目标:优化分配机制,获得多数人类支持
- 结果:AI设计出好的机制,且获得了多数投票
- 结论:民主AI是解决“价值对齐问题”的策略创新
研究动机
未充分探索的前沿领域:将AI应用于人文社科(协助人类设计“促进社会公平繁荣”的机制)
要解决的问题:价值对齐问题
- 定义:如何让AI的行为模式符合真实人类的价值观和行为习惯
- 挑战:人类社会存在多元观点,AI难以明确应该与哪种偏好保持一致
- 解决思路:加大“从人类直接学习价值观”的力度
构建行为模式符合人类偏好的人工智能系统,这一挑战被称为"价值对齐"问题。
研究目标
提出:一种人类参与的研究pipeline“民主AI”
- 定义:不由研究者预先规定正确价值观,通过人类投票来决定AI应该学什么、做什么的价值对齐方法
- 目标:训练智能体,设计出人类偏好、并愿意在多数制选举中投票支持实施的策略
我们结合现代深度强化学习与调解冲突观点的古老技术——人类选民的多数决民主——开发出以人为中心的研究流程,用于推进价值对齐的人工智能研究。
与其先验地赋予智能体所谓的人类价值观——这可能导致系统偏向研究者的偏好——我们更倾向于训练它们实现民主目标:设计出人类青睐的政策,从而在多数决选举中获得投票支持。
我们将这种方法称为"民主AI",它是对近期相关参与式方法的延伸。
实验内容、结论
验证民主AI的有效性
实验场景:投资博弈
图1a:投资博弈示意图
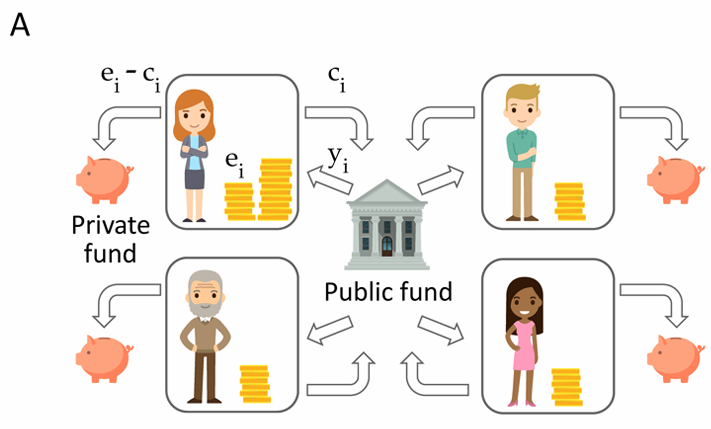
- 开始前准备:确定每位的玩家初始资金
- Head玩家1名,固定分得10金币
- Tail玩家3名,统一随机{2,4,6,8,10}金币(实验1中为{2,4,10})
- 玩家i每回合都会获得等量的初始资金ei
- 单人回合流程:
- 将$e_i$中整数个金币$c_i$分配至公户,剩余$e_i-c_i$存入私户
- 公户资金乘以统一增长系数r=1.6
- 按照再分配机制将公户资金分配给每位玩家,玩家i获得$y_i$
- 玩家i本回合总收益为:$e_i-c_i+y_i$
- 玩家数>=4,总投入增长系数r=1.6(人均边际回报率MPCR=r/n=0.4<1)
- MPCR=0.4:投入1,每人平均获得0.4
- 总体有利,但平均分配下个人亏损
- 再分配机制:根据玩家的贡献额与初始资金,确定公共投资总额中返还给每位玩家的比例。
- 左倾机制:结果平等,即使没有投入也能分到钱,极端:平均分配
- 右倾机制:个人责任,投入越多分得越多,极端:完全按贡献分配
实验1
实验1展示了三种Baseline机制:严格平均主义(strict egalitarian)、自由主义(libertarian)和自由平均主义(liberal egalitarian)。
实验设置:
- 756个参与者分配为4人小组
- Head玩家1名:固定分得10金币
- Tail玩家3名:统一随机{2,4,10}金币
游戏规则:
每个小组进行多轮游戏,每轮10回合,每次游戏初始分配相同,但采用不同的再分配机制。
每种再分配机制均根据玩家自身及他人的公共贡献,以不同函数形式确定玩家i的收益y。
玩家必须通过实践学习每种机制的运作方式。
三种Baseline机制与实验结果:
- 严格平均主义:将公共资金平均分配给所有参与者,无论贡献
- $y_i=\frac{r \times \sum c}{n}$
- 问题:每个个体通过拒绝贡献(ci=0)、搭便车享受其他参与者的慷慨付出而获益
- 实验结果:随着时间推移,贡献度随时间递减,与上述结果一致
- 自由主义:按贡献比例向每位玩家分配收益
- $y_i=r \times c_i$
- 最优策略为ci=ei(全部投入),实现了贡献的私有化,激励参与者增加贡献
- 实验结果:随着时间推移,贡献度逐渐增加
- 自由平均主义:按投入占自身初始资金的比例分配收益
- $y_i=\frac{c_i}{e_i} \times r \times \sum c$
- 主张每位玩家对行为而不对初始资金负责
- 实验结果:Tail玩家提高贡献度,Head玩家较平稳(不愿意多贡献)
图1c:三种Baseline机制下,不同玩家的相对贡献率随游戏回合变化趋势
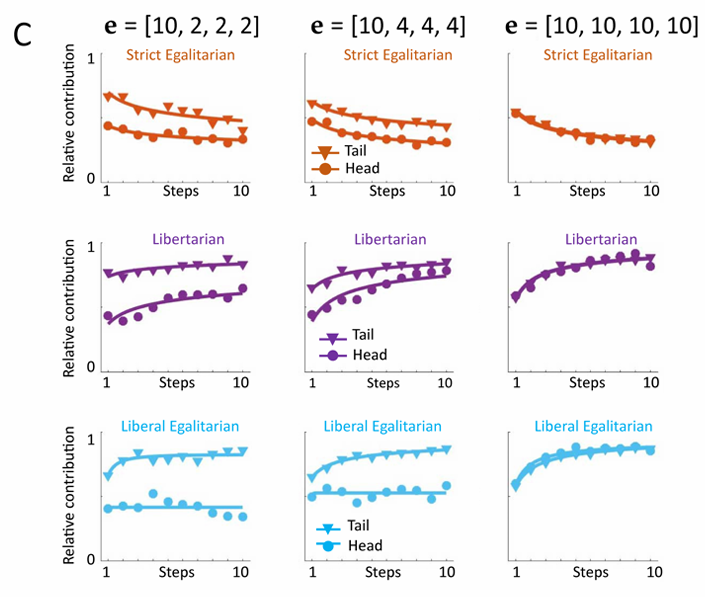
有研究表明初始资源分配的不均等或人均边际回报率(MPCR)的变化会影响玩家的贡献度。
当Tail玩家获得等额(10)或较低(2、4)初始资源时,Head玩家的贡献量呈现显著差异。
由此可见,生产力在不平等程度加剧的条件下受到抑制。
实验1结论:机制设计的解空间大,不同机制具有不同问题,本文探究AI系统能否设计出优于这些方案、更受人类青睐的机制
Human-in-the-loop pipeline
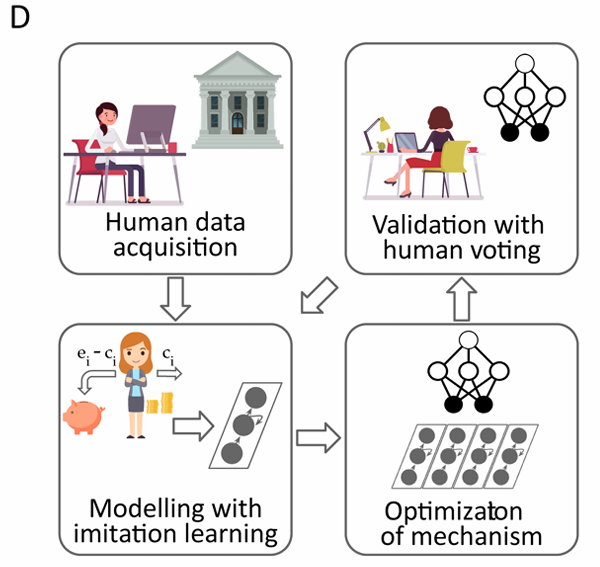
- 数据采集:收集人类行为的初始样本
- 建模:RNN构建虚拟人类玩家,学习遵循与真人玩家相同的行为
- 优化:运用DRL优化机制设计,通过“策略梯度法”最大化虚拟人类玩家的投票数
- 迭代:抽取新的人类参与,让RL设计的再分配机制与基准方案进行对比,收集数据重复2,3步骤
通过该流程获取的新机制称为:人本再分配机制(Human-Centered Redistribution Mechanism,HCRM)
问题建模
将三种Baseline推广为连续参数化的再分配机制解空间,称为ideological manifold
$$y_i=v(y_i^{rel})+(1-v)(y_i^{abs})$$
- $v$:混合参数,控制相对和绝对分配的权重
绝对分配:
$$y_i^{abs}=r[w(c_i)+(1-w)(c_{-i})]$$
- $c_i$:玩家i的贡献
- $c_{-i}$:其他玩家的平均贡献
- $w$:控制个人贡献和他人贡献的权重
相对分配:
$$y_i^{rel}=r(\dfrac{C}{P})[w(\rho_i)+(1-w)(\rho_{-i})]$$
- $\rho_i=c_i/e_i$:玩家i的贡献率
- $\rho_{-i}$:其他玩家的平均贡献率(贡献占初始资金的比例)
- $C$:玩家贡献总和
- $P$:玩家贡献率总和
三种Baseline机制对应的参数设置:
- 严格平均主义:$v=1,w=1/k \Rightarrow y_i=C/k$,k为玩家数
- 自由主义:$v=0,w=1 \Rightarrow y_i=r \times c_i$
- 自由平均主义:$v=1,w=1 \Rightarrow y_i=r \times C \times \dfrac{\rho_i}{P}$
| 机制 | $v$ | $w$ | $y_i$ |
|---|---|---|---|
| 严格平均主义 | 1 | 1/k | $r \times C / k$ |
| 自由主义 | 0 | 1 | $r \times c_i$ |
| 自由平均主义 | 1 | 1 | $r \times C \times \dfrac{\rho_i}{P}$ |
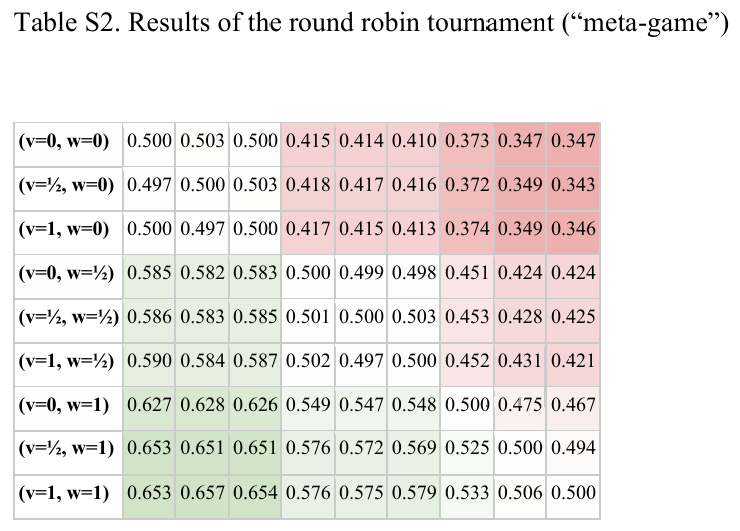
抽样出一系列再分配机制两两solo,取得票数最高的机制是自由平均主义。
实验2
实验2将AI设计的HCRM机制与三种Baseline机制进行对比评估
实验设置:
- 2508个参与者分配为4人小组
- Head玩家1名:固定分得10金币
- Tail玩家3名:统一随机{2,4,6,8,10}金币
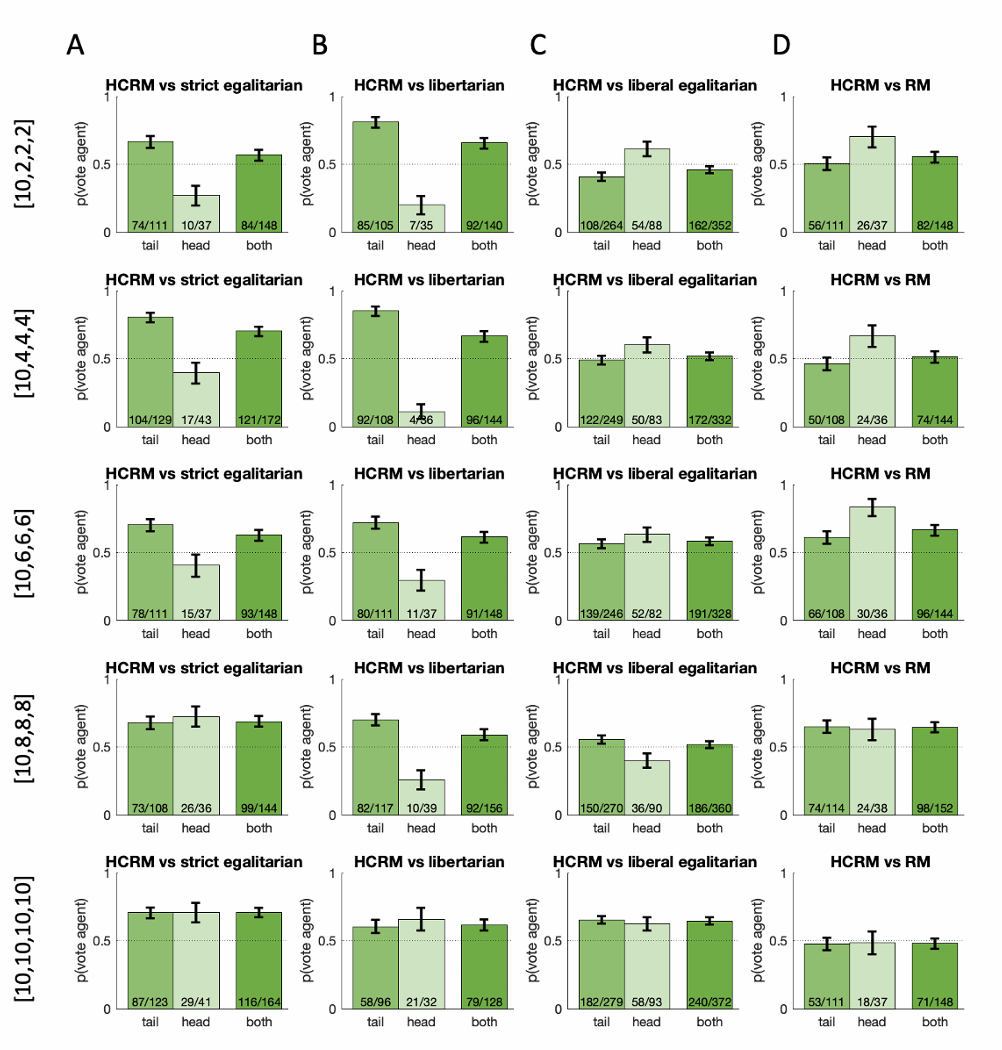
实验结果:
- HCRM对比3种Baseline机制的得票率:严格平均66.2%,自由主义60.8%,自由平均主义54.5%
- 在不同的Tail玩家初始资金设置下,HCRM在绝大多数情况下能获得更多投票
- 在极端不平等情况下(Tail玩家初始资金2),自由平均主义略优于HCRM(47.4%)
实验2结论:HCRM机制在投票中优于3种Baseline机制,说明民主AI能设计出更符合人类偏好的机制
图2:HCRM与Baseline机制、RM机制(后文介绍)的对比结果
实验3
实验3是一个消融实验,证明构建虚拟人类玩家模型在制定合理机制中的重要性。
假定玩家完全理性,不使用人类行为数据训练,使用纯理性Agent代替虚拟人类玩家。
它们的目标是最大化预期收益,而不是模仿人类决策,其余条件和HCRM一致。
将这样得到的理性机制(Rational Mechanism,RM)与HCRM进行对比。
实验设置:756个参与者,其余设置同实验2
实验结果:HCRM获得57.2%的投票,具体如图2d
值得注意的是,在资源分配不均的条件下,RM形成了极端策略——该策略忽视头部玩家,主要向尾部玩家分配收益。
然而,尽管尾部玩家与头部玩家的比例更有利,这种策略即使在最不平等的分配条件下也未能成功。
因为头部玩家会迅速停止贡献,损害所有人的利益(包括尾部玩家),导致整体群体盈余低于HCRM策略。
换言之,人类偏好的再分配政策既非平均分配公共资源,也非仅顾及多数资源匮乏者的利益。
实验3结论:HCRM优于RM,说明人类行为数据对设计符合人类偏好的机制至关重要
HCRM机制分析
- a:海滩图,横轴为$\rho_{Head}$,纵轴为$\rho_{Tail}$,暖色代表Head玩家分得更多,冷色代表Tail玩家分得更多。
- 注:主要看Tail低Head高、Tail高Head低的颜色分布
- b:各组盈余(对数单位)与基尼系数的二维分布图。颜色越浅表示密度越高,基尼系数越低意味着平等程度越高。
- c:各机制与初始资源条件下贡献与回报的关系,每个点代表单场博弈中的头部玩家或尾部玩家平均值,阴影区域显示点密度分布。
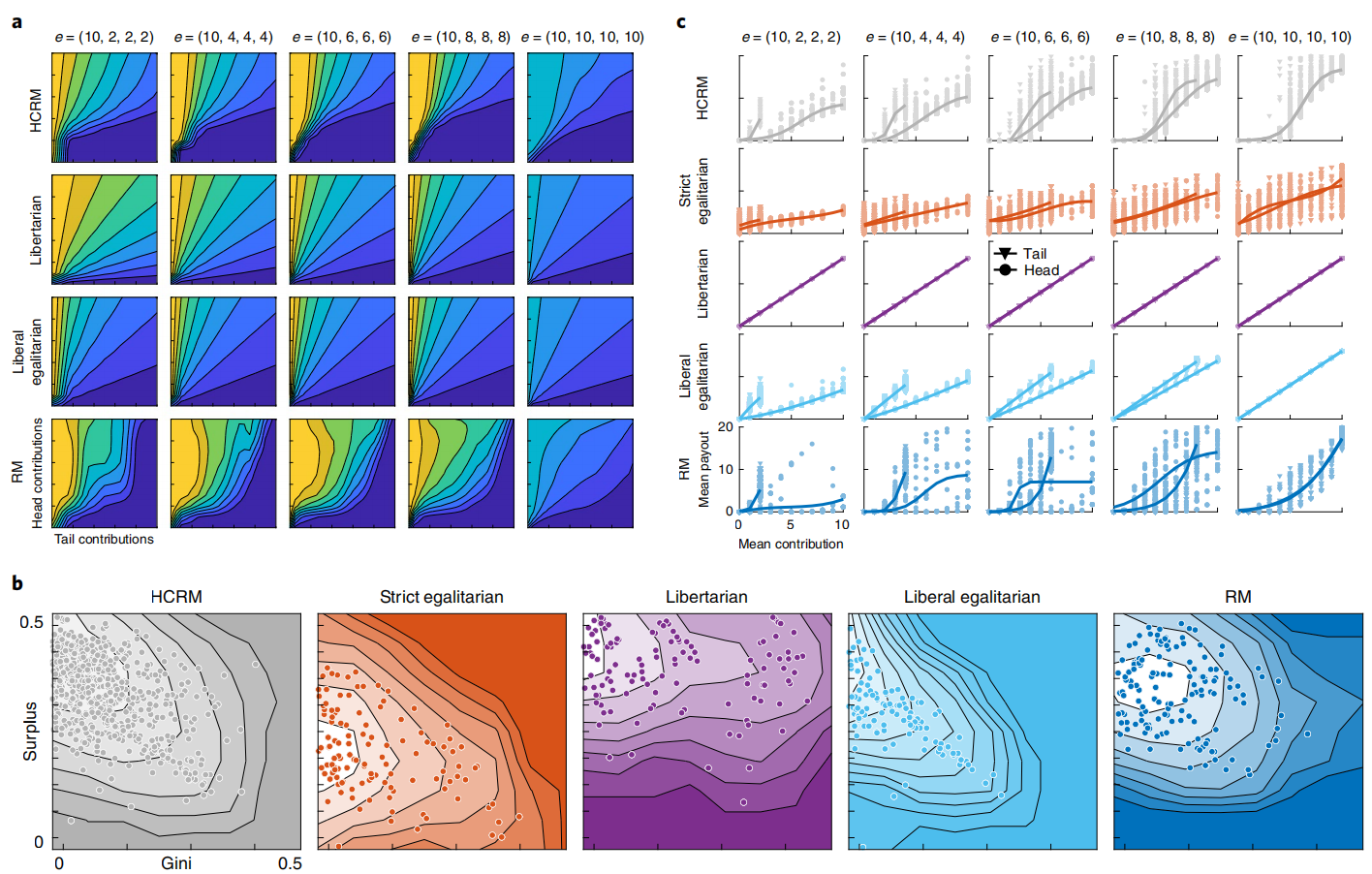
- HCRM总体采用了自由平等主义,根据贡献度进行补偿,合理牺牲Head玩家利益,缓解不平等。
- 在生产效率(总盈余)和公平性(基尼系数)之间取得了良好平衡。(图3b)
- 惩罚低贡献、搭便车:除非玩家投入了大约其初始禀赋的一半,否则该机制几乎不会给予任何回报。(图3c)
- 融合了多种分配制度的思想元素。
实验4
让参与过游戏的人类玩家设计再分配机制,与HCRM进行对比
实验设置:
- 61个机制设计者
- 244个参与者分配为4人小组
- 初始资金:(10,4,4,4)
实验结果:HCRM获得62.4%的投票,具体如图4
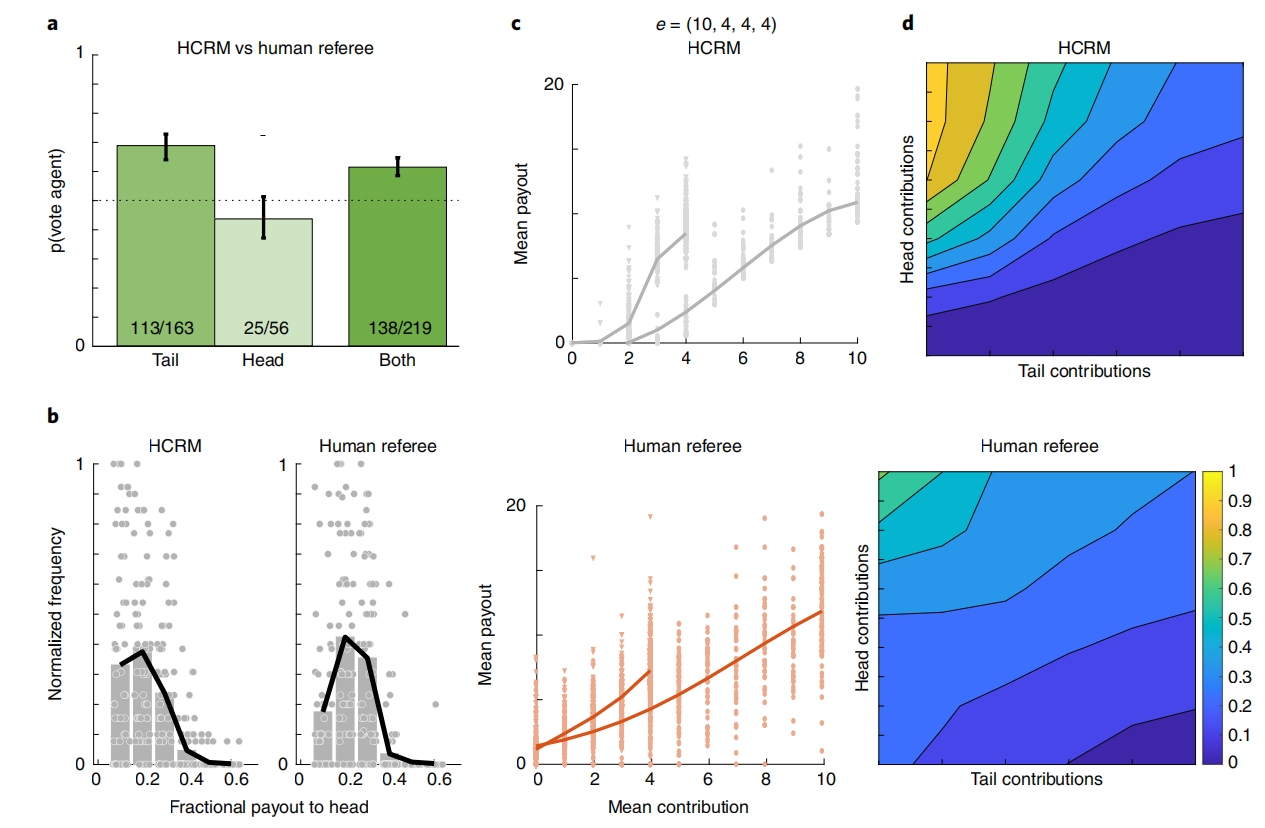
人类设计的机制存在的问题:在分配收益时总体上对贡献的响应程度较低(海滩图)
- 对Head玩家低回报
- 未能充分奖励努力贡献的Tail玩家
实验4结论:HCRM优于人类设计的机制,说明民主AI能设计出更符合人类偏好的机制
讨论 Discussion
- AI可以通过“民主偏好”这一目标函数实现价值对齐。
- 让AI的优化目标为“多数人愿意投票支持”,缓解偏见问题
- 民主AI继承了民主制度的经典风险“多数人的暴政”
- Future:额外引入对少数群体的制度性保护
- AI设计的机制的可解释性不足
- AI设计的机制得票率高于人类设计的机制
- 人们是否会信任AI系统代替人类来设计的机制?
- 反对AI政府,强调人类最终控制权
方法
投资博弈 Investment game
4轮游戏分别有10、10、10、4回合
- 开始前准备:确定每位的玩家初始资金
- Head玩家1名,固定分得10金币
- Tail玩家3名,统一随机{2,4,6,8,10}金币(实验1中为{2,4,10})
- 玩家i每回合都会获得等量的初始资金ei
- 单人回合流程:
- 将$e_i$中整数个金币$c_i$分配至公户,剩余$e_i-c_i$存入私户
- 公户资金乘以统一增长系数r=1.6
- 按照再分配机制将公户资金分配给每位玩家,玩家i获得$y_i$
- 玩家i本回合总收益为:$e_i-c_i+y_i$
- 阶段详解:
- 阶段1:教程,模拟10回合,帮助玩家熟悉游戏规则
- 阶段2,3:正式游戏,分别以不同的再分配机制A,B进行10回合游戏
- 阶段4:机制A/B再次出现的概率等于该机制在4名参与者投票中所获比例,进行4回合游戏,一致投票来验证结果
训练虚拟玩家
- 训练方式:模仿学习
- 数据:真实人类参与者的游玩数据
- 网络:RNN
- 输入(每时间步):4个玩家的初始资金、上一轮的{贡献、相对贡献、收益}
- 输出:玩家在下一轮贡献的预测
- 网络架构:
- Linear: out_dim=64, tanh
- LSTM: hidden_dim=16
- Linear: out_dim=11, softmax,代表贡献0-10的概率分布
- 时序反向传播
- 损失函数:预测贡献与真实贡献的交叉熵+正则项
- 预测分布的熵,鼓励多样性
- 参数的 L2 正则项,防止过拟合
投票机制
$$p(A) = \Phi[rpay_A - rpay_B]$$
- $p(A)$:选择机制A的概率
- $rpay=\sum \dfrac{y_i}{e_i}$:相对收益之和
- $\Phi$:logistic函数,s=1.4(无关)
- 式子来源:实验发现投票选择与rpay高度相关
机制设计与迭代
问题定义和设置
- MD:用于设计再分配机制的神经网络(机制设计者,Machine Designer)
- 学习:强化学习一个函数(再分配机制),将观测量(博弈状态)映射为分配权重
- 架构:基于GNs,对参与者顺序具有等变性
- 目标:最大化虚拟玩家在与对照机制进行比较时,对它的机制投赞成票的累计概率
- HCRM:MD训练收敛后所产生的具体机制(人本再分配机制,Human-Centered Redistribution Mechanism)
网络架构
- 输入:dim=12,4个玩家的初始资金、贡献、相对贡献
- 输出:softmax归一化的4个玩家的权重
- 无记忆:输入中不包含历史回合的数据、结构中不包含循环或递归机制
更新过程:
- 初始:完全图网络$(u,V,E)$,参与者属性v,边属性、全局属性u均为空
- 更新边属性:$e_{s,r}'=\phi_e(e_{s,r},v_s,v_r,u)$
- 更新节点属性:$v_r’=\phi_v(\sum_{s} e_{s,r}',v_r,u)$
- 更新全局属性:$u’=\phi_u(\sum_{s,r} e_{s,r}‘,\sum_{r} v_r’,u)$
两个串联的、具有4个节点的有向完全图,u为全局属性,V为节点集,E为边集
- GN1:$𝜙_e, 𝜙_v, 𝜙_u$ 实现为独立线性层,out_dim=32, tanh
- GN2:
- $𝜙_e$: out_dim=32, tanh
- $𝜙_v$: out_dim=1, tanh
- $𝜙_u$: 无
训练算法
- 估计(Estimator):基于随机计算图(Stochastic Computation Graphs, SCG),近似计算目标函数相对于策略参数(图网络的权重)的梯度
- 优化器:RMSProp
- 迭代轮数:10000
- 学习率:0.0004
- Epsilon:1e-5
- decay:0.99
每轮:512场游戏,Tail玩家初始资金{2,3,4,5,6,7,8,10}各64场
HCRM vs Baseline(自由平等主义,在ideological manifold中得票率最高的机制)
$$
S = J + \perp(J) \times \sum _i \sum _{t=2}^{10} \log p(\perp(c_i^t))
$$
- S:替代目标函数
- J:预期获得的选票数(主目标),mean-centered,降低方差
- 第二项:第二项:引入分配机制变化影响贡献,进一步影响投票结果的考虑
- $\perp$:停止梯度操作
Note
- 领域:将AI应用于人文社科,设计出人类青睐的政策
- 问题:Value Alignment (人机)价值对齐
- 如何让AI的行为模式符合人类的价值观和行为习惯
- 挑战:社会存在多元观点,AI难以明确应该与哪种观点保持一致
- DAI定义:不预先规定正确价值观,通过人类投票来决定AI应该学什么、做什么的价值对齐方法
- 实验:投资博弈游戏(Investment Game)
- 如何使用民主AI方式制定出人类偏好的分配策略